Storytelling with Data: Do you want to learn how to communicate effectively with data? Do you want to impress your boss, clients, and colleagues with your data-driven insights and recommendations? Do you want to master the art and science of storytelling with data?
If you answered yes to any of these questions, then this blog post is for you. In this post, I will share with you some tips and tricks on how to use data storytelling to enhance your business communication skills and achieve your goals.

What is data storytelling?
Data storytelling is the process of creating and delivering a narrative that explains, illustrates, or persuades using data as evidence. Data storytelling combines three elements: data, visuals, and narrative.
Data is the raw material that provides the facts and figures that support your message. Visuals are the graphical representations that help you display and highlight the key patterns, trends, and insights from your data. A narrative is a verbal or written explanation that connects the dots and tells a coherent and compelling story with your data.
Why is data storytelling important?
Data storytelling is important because it helps you:
- Capture and maintain your audience’s attention. Data storytelling makes your message more engaging and memorable by using visuals and narrative techniques that appeal to human emotions and curiosity.
- Simplify and clarify complex information. Data storytelling helps you distill and organize large amounts of data into meaningful and actionable insights that your audience can easily understand and relate to.
- Influence and persuade your audience. Data storytelling helps you establish credibility and trust by backing up your claims with evidence. It also helps you motivate and inspire your audience to take action by showing them the benefits and implications of your data analysis.
How to create a data story?
Creating a data story is not a one-size-fits-all process. It depends on various factors such as your audience, your purpose, your data, and your medium. However, here are some general steps that can guide you in crafting a data story:
- Define your audience and your goal. Before you start working on your data story, you need to know who you are talking to and what you want to achieve. Ask yourself: Who is my audience? What do they care about? What do they already know? What do they need to know? What do I want them to do or feel after hearing my story?
- Find and analyze your data. Once you have a clear idea of your audience and your goal, you need to find and analyze the data that will support your message. Ask yourself: What data sources are available and relevant? How can I clean, transform, and explore the data? What are the key insights and patterns that emerge from the data?
- Choose your visuals and narrative techniques. After you have identified the main insights from your data, you need to choose how to present them visually and verbally. Ask yourself: What type of chart or graph best suits my data and my message? How can I design my visuals to make them clear, attractive, and effective? What narrative techniques can I use to structure my story and make it interesting and persuasive?
- Deliver your data story. The final step is to deliver your data story to your audience using the appropriate medium and format. Ask yourself: How can I tailor my delivery to suit my audience’s preferences and expectations? How can I use verbal and non-verbal cues to enhance my presentation skills? How can I solicit feedback and measure the impact of my data story?
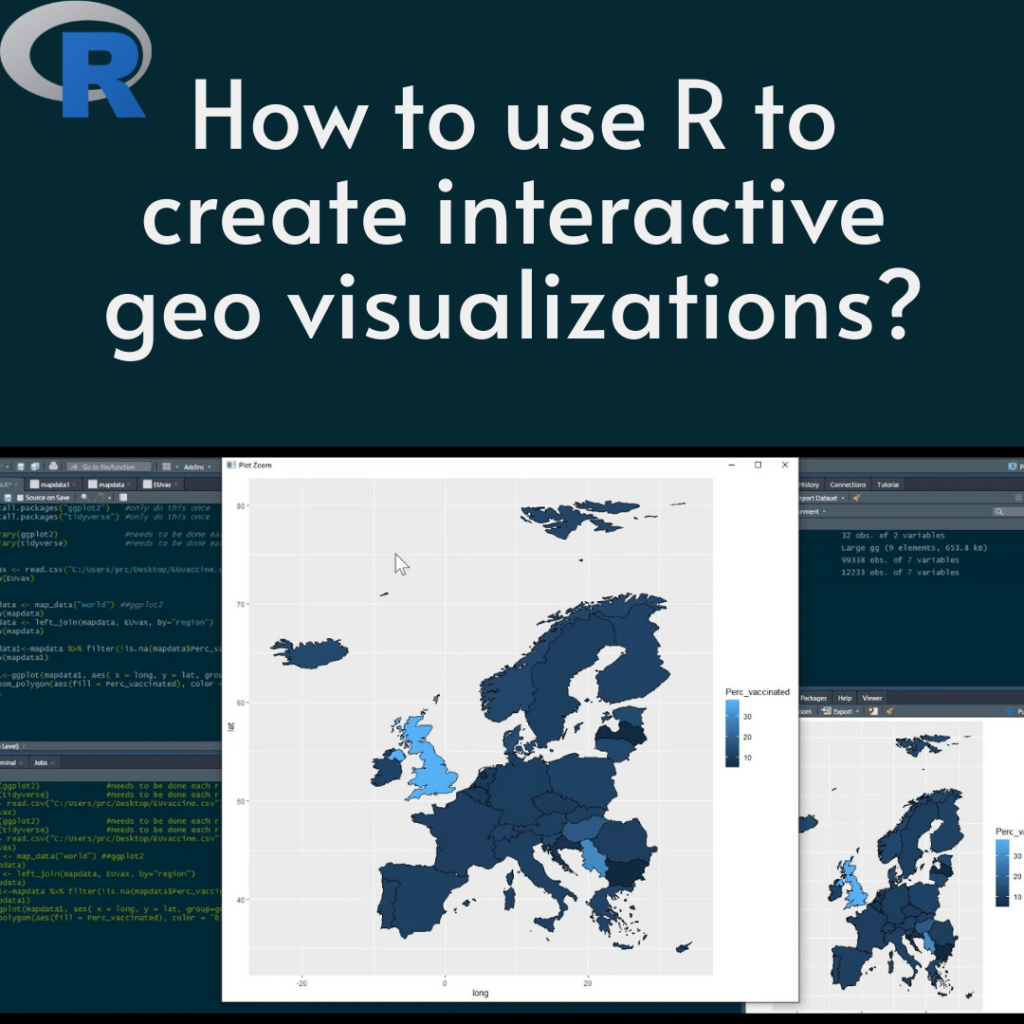
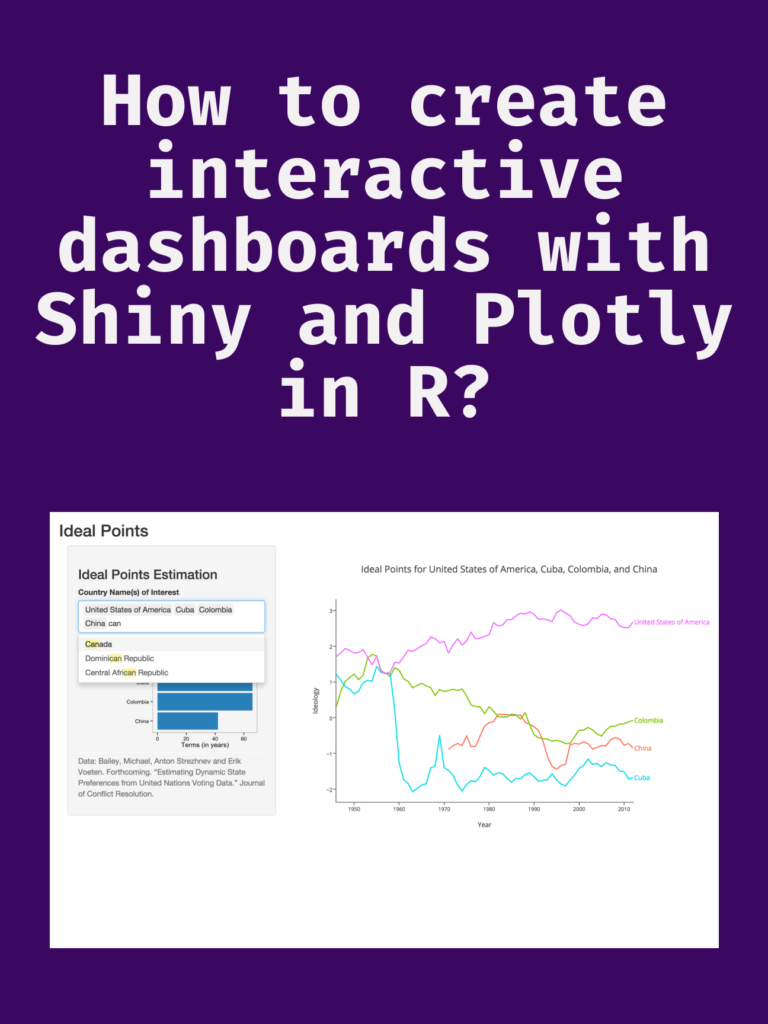
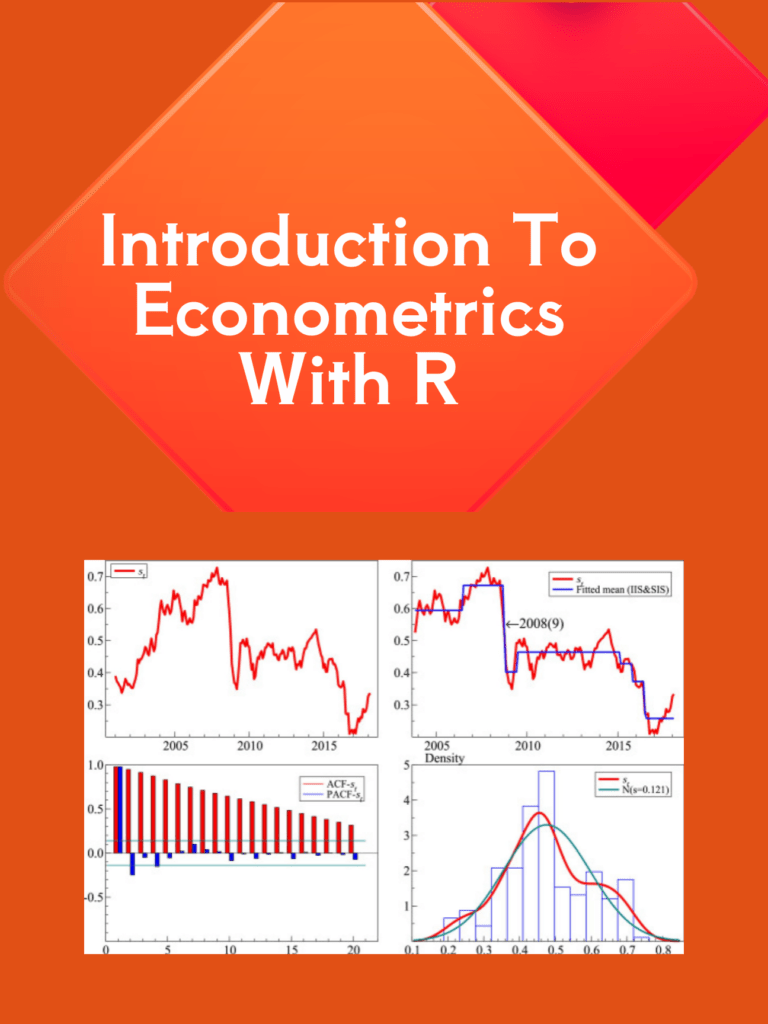
Read more: Data Visualization and Exploration with R