A box plot is a graphical representation of a dataset that displays the distribution of data through five summary statistics: the minimum value, the first quartile (25th percentile), the median (50th percentile), the third quartile (75th percentile), and the maximum value. The box in the plot represents the middle 50% of the data (between the first and third quartiles), while the whiskers extend from the box to show the range of the data, excluding any outliers. Outliers are represented by dots or asterisks outside the whiskers. Box plots are useful for quickly visualizing the spread, skewness, and outliers of a dataset. They are commonly used in statistical analysis, especially for comparing distributions between different groups or variables.

Download:
To make a boxplot in R, you can use the boxplot() function, which is a built-in function in R. Here’s an example code:
# Create a vector of data
data <- c(10, 20, 15, 30, 25, 35, 40, 50)
# Create a boxplot of the data
boxplot(data)
In the above example, we first create a vector of data called data. Then we use the boxplot() function to create a boxplot of the data.
You can customize the boxplot by adding different parameters to the boxplot() function. Here are some examples:
- Adding a title to the plot:
boxplot(data, main="Boxplot of Data")
- Changing the x-axis label:
boxplot(data, xlab="Data")
- Changing the color of the box and whiskers:
boxplot(data, col="blue")
- Creating a horizontal boxplot:
boxplot(data, horizontal=TRUE)
These are just a few examples of how you can customize the boxplot in R. You can find more information about the boxplot() function and its parameters in the R documentation.
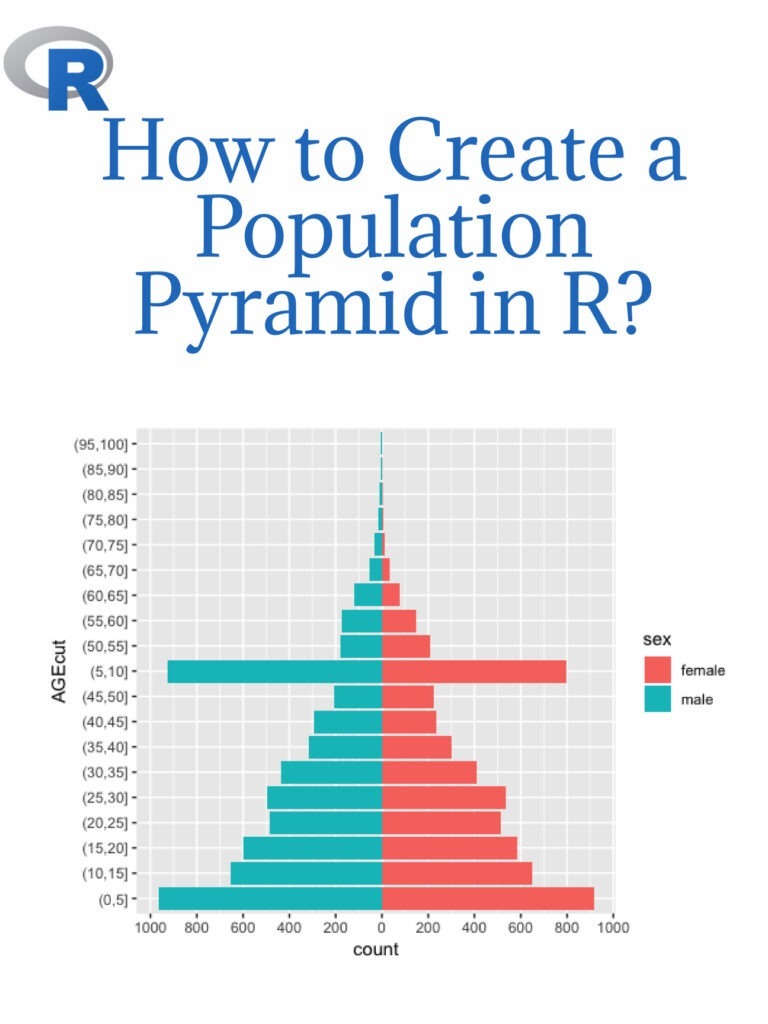
Read more: How to Create a Population Pyramid in R?