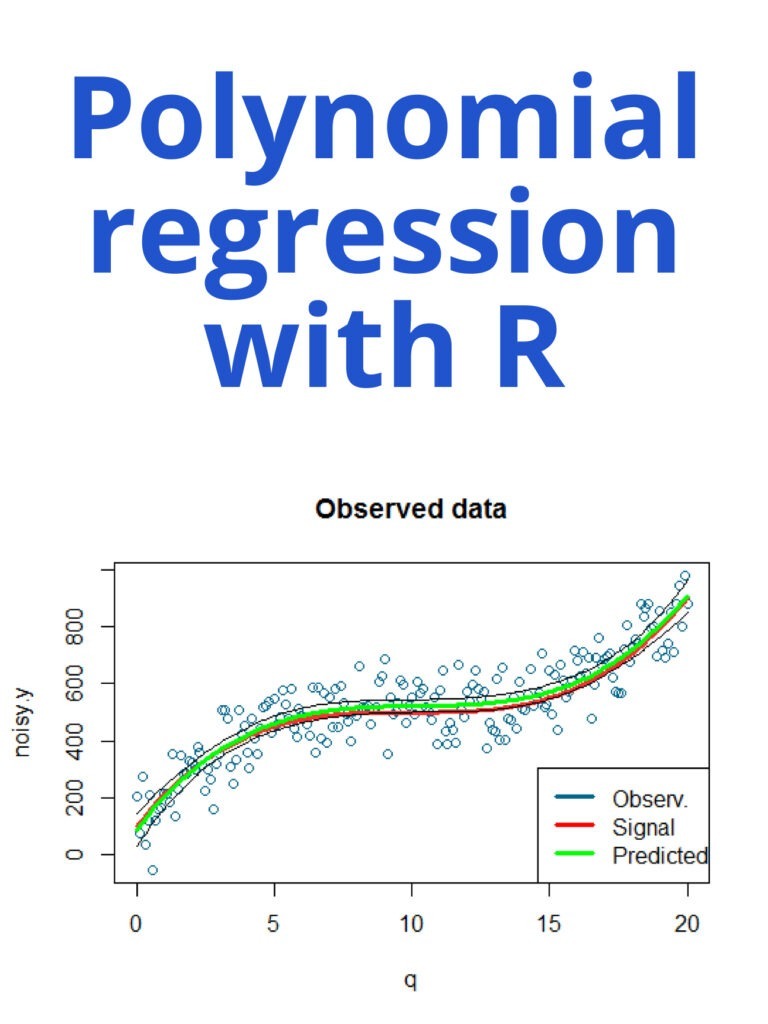
A line graph is a type of chart used to display data as a series of points connected by lines. It is commonly used to show trends over time or to compare multiple data sets. Line graphs are useful for visualizing data that changes continuously over time, such as stock prices, weather patterns, or population growth. They can also be used to compare multiple data sets, such as the performance of different companies in a particular industry. To create a line graph in R, you can use the built-in plot() function or the more powerful ggplot2 library. Here is an example of how to create a line graph using ggplot2.

First, let’s create a sample data frame with some random values:
# Create sample data frame
x <- 1:10
y <- c(3, 5, 6, 8, 10, 12, 11, 9, 7, 4)
df <- data.frame(x, y)
Next, we’ll use ggplot() to create a plot object, and then add a geom_line() layer to draw the line:
# Load ggplot2 library
library(ggplot2)
# Create plot object
p <- ggplot(df, aes(x, y))
# Add line layer
p + geom_line()
This will create a basic line graph with the x values on the x-axis and the y values on the y-axis. You can customize the appearance of the graph by adding additional layers or modifying the ggplot() object. For example, you can add axis labels and a title:
# Add axis labels and title
p + geom_line() +
labs(x = "X-axis label", y = "Y-axis label", title = "Title of the graph")
You can also modify the line color and thickness using the color and size arguments of geom_line():
# Change line color and thickness
p + geom_line(color = "red", size = 2) +
labs(x = "X-axis label", y = "Y-axis label", title = "Title of the graph")
These are just a few examples of the many customization options available in ggplot2.